Windows 存储池 RAID1 虚拟磁盘降级的问题
今天早上看到监控邮件,git 和 nexus 服务都挂了,赶紧登录服务器看了下,果然,又是磁盘出问题了。存储池的一个 Mirror 的虚拟磁盘出现警告,提示已降级,其中一块物理磁盘显示“不正常:介质故障,IO 错误”,如下图:
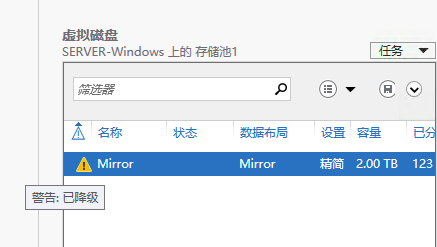
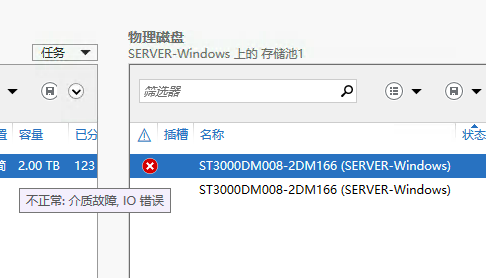
3 月份的时候,也出现过同样的问题,当时刚开始误以为是物理硬盘出了问题,但是检测下来磁盘 S.M.A.R.T. 数据是正常的,检查了坏道,也全部正常。后来把失败的物理磁盘拔下来准备寄回检修的时候,发现存储池的虚拟磁盘提示数据不完整,虽然是 RAID1,但是单靠剩下那一个硬盘还不足以恢复数据,尴尬。当时的处理办法是把两块磁盘都插上,虽然提示降级,但是数据是完整的,数据可以拷贝出来。拷贝出来后把整个存储池删了重建,再把数据拷进去,就正常了。当时也没多想。
今天又出现了同样的问题,出错的磁盘是另一块物理磁盘,这更加确定了该问题不是物理磁盘的锅,可能是存储池的问题。但是不想再通过上次的方法暴力解决。不过还是先把数据都拷贝出去了,以防万一。
尝试修复虚拟磁盘,没用,通过 Get-StorageJob 查看一直是 Suspended 的状态,直接用 PowerShell 执行 Repair-VirtualDisk,提示 Repair-VirtualDisk : Not enough available capacity(没有足够的可用容量)。


删除和重置物理磁盘都无法成功,提示需要先修复虚拟磁盘才行。
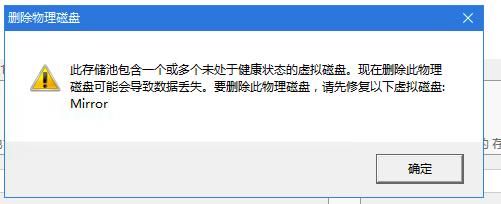
后来发现一个系统更新,KB4093120,挺大的,去找了下更新内容,发现如下一条:
Addresses an issue that may generate a capacity reserve fault warning during cluster validation or while running the Debug-StorageSubSystem cmdlet even though enough capacity is actually reserved. The warning is "The storage pool does not have the minimum recommended reserve capacity. This may limit your ability to restore data resiliency in the event of drive failure(s)."
修复了在群集验证期间或运行 Debug-StorageSubSystem cmdlet 时可能生成容量保留错误警告(即使实际上保留了足够的容量)的问题。 警告内容为“存储池没有建议的最低保留容量。 这可能会限制在驱动器发生故障时恢复数据弹性的能力。”
可能是引起这个问题的原因,等待更新之后再尝试下。
更新之后发现问题依旧存在。沮丧。
突然想到没有足够的空间可能并不是指存储池的剩余空间,而是可能需要添加一个硬盘,作为临时备份的磁盘。于是找来一个移动硬盘,插上去,添加到存储池中,设置为 AutoSelect。果然,虚拟磁盘的修复开始了。等待修复结束,把提示“介质故障,IO 错误”的硬盘删除掉重新添加进来,然后通过 Get-PhysicalDisk -SerialNumber 42H1YCTHF | Set-PhysicalDisk -Usage Retired 把移动硬盘手动设置为 Retired,然后在物理磁盘的页面把移动硬盘从存储池删除掉,等待同步完成,就恢复成原样了。
以上便是该问题的解决办法,至于原因,暂时还不得而知。
出现这个错误之前,在系统事件里面,会有不少来源于 Disk 的警告和错误:
- 事件 ID 为
154的错误:由于硬件错误,磁盘 0 (PDO 名称: \Device\00000055)的逻辑块地址 0xb5ae5d0 处的 IO 操作失败 - 事件 ID 为
153的警告:已在磁盘 0 (PDO 名称: \Device\000000a5)的逻辑块地址 0x0 处重试 IO 操作。 - 事件 ID 为
51的警告:传呼期间在设备 \Device\Harddisk4\DR4 上检测到一个错误。
从注册表中 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Disk\Enum 这个目录里面可以看到磁盘 ID 对应的磁盘。
问题是硬盘检测下来是好的,没有坏道,并且上次出问题的硬盘,这次一次错误都没有。
有可能是 SATA 接口的问题,接触不良之类的。上次出问题之后两个硬盘都拆下来重新安装过,可能 SATA 接口换过了。这个具体后面再研究下。
2018-05-03 更新:
买了两根绿联的 SATA 线换了下,目前为止没有再次发现这个错误。感觉果然是 SATA 线的问题。
1. 存储池开机自动连接虚拟磁盘
最近修复存储池的问题,不知道为啥,有个虚拟磁盘可能是之前分离过,现在每次重启之后都需要手动连接,很麻烦,可通过 Get-VirtualDisk 命令查看虚拟磁盘状态,结果如下:
FriendlyName ResiliencySettingName OperationalStatus HealthStatus IsManualAttach Size
------------ --------------------- ----------------- ------------ -------------- ----
Simple Simple OK Healthy False 1 TB
Mirror Mirror OK Healthy True 5 TB
其中的 IsManualAttach 便是手动连接的属性,我们的这块名为 Mirror 的虚拟磁盘的 IsManualAttach 属性值为 True,所以不会自动连接了。
通过如下命令可将其设为自动挂载:
Set-VirtualDisk -FriendlyName Mirror -IsManualAttach $False
或者通过如下命令将所有手动挂载的磁盘设为自动挂载:
Get-VirtualDisk | Where-Object {$_.IsManualAttach –eq $True} | Set-VirtualDisk –IsManualAttach $False
2. 发现了服务器的一个大问题
今天拆机发现硬盘很烫,想想不应该啊,摸了下 CPU 风扇,发现往里吹热气,往外的是冷风。😳!我的 CPU 风扇是两边都是风扇的,安装的时候没注意,竟然装反了!导致一直外往里吸气。难怪上面全是灰!!!尴尬了。赶紧淘宝买了一支 7783 的导热硅脂,重新安装一下,顺便清个灰。
安装前后的数据对比:
风扇装反的情况下
- 正常开机 6 小时,CPU 温度 38℃,硬盘温度 40℃。
- 挖矿软件设置 60%的 CPU 使用率,挖矿 10 分钟左右,CPU 温度 62℃ 左右,硬盘温度 42℃。
- 挖矿软件设置 60%的 CPU 使用率,挖矿 60 分钟左右,CPU 温度 64℃ 左右,硬盘温度 45℃。
- 挖矿软件设置 60%的 CPU 使用率,挖矿 03 小时左右,CPU 温度 65℃ 左右,硬盘温度 48℃。
重新换过导热硅脂,风扇装正的情况下:
- 正常开机 10 分钟,CPU 温度 34℃,硬盘温度 31℃。
- 挖矿软件设置 60%的 CPU 使用率,挖矿 10 分钟左右,CPU 温度 55℃ 左右,硬盘温度 36℃。
- 挖矿软件设置 60%的 CPU 使用率,挖矿 60 分钟左右,CPU 温度 58℃ 左右,硬盘温度 42℃。
2018-05-04 更新:
解决完事件查看器里面其他几个错误,然后重启之后,发现再次出现 Disk 51 和 Disk 154 的错误。不过频率很低,可能还是由于接触的问题。
2018-05-23 更新:
今天发现服务器上的服务挂了很久,登上去看,发现 D 盘不见了,尝试重启,等待了很长时间重启完成,可能在更新系统。重启进入后发现 D 盘出现了,但是硬盘一直出现不断重启的声音,事件里面每隔 5-6 秒钟就会出现一个 已在磁盘 4 (PDO 名称: \Device\Space2)的逻辑块地址 0x1f52d368 处重试 IO 操作。 的警告,并且伴随着错误 由于硬件错误,磁盘 2 (PDO 名称: \Device\0000003e)的逻辑块地址 0xaa1dde8 处的 IO 操作失败。,磁盘 1、2、4 都有警告,磁盘 1、2 有错误。之后手动拔了磁盘 ID 为 2 的物理磁盘(W5033A6K)的 SATA 线,然后重新插上,发现没有重启的声音了,错误警告也停止了,但虚拟磁盘出现“不正常,未知”的状态。感觉不像是接触不好的问题,因为我动了线没效果,拔了重插才有效果。看了下之前的日志,磁盘 0 是固态硬盘,莫非是系统盘的锅?固态硬盘检测也没有坏道。
2018-06-08 更新:
前几天重装了系统,仍然出现了问题。6 号 18:03:06、6 号 20:01:13、7 号 6:16:47、7 号 6:17:11、7 号 6:20:22 都出现了 Disk 154 的错误。根据之前多次出错的事件来看,凌晨 6 点多是报这个错误的高发期,得先搞明白为啥,这个时间段在做什么。
网站报警显示 8 号 2 点 06 分挂了,Hyper-V 虚拟机已经关机了,虚拟机返回的错误如下:
“ubuntu-01”: 虚拟硬盘“D:\虚拟机\Virtual Hard Disks\ubuntu-nas_E27174DE-7800-4F8C-918C-097516949C09.avhdx”检测到可恢复的错误。当前状态: 磁盘已满。(虚拟机 ID 3695BB9F-3BAA-4D94-938F-0C197B9AA34D)
应该是存储空间无法写入导致的。
2018-06-26 更新:
前几天重新买了个主板,安装时发现硬盘的电源线插口有点鼓起来变形了,感觉是温度高热胀冷缩的原因。当时手动压扁了安装了。稳定了几天没问题,今天又出问题了。现在有点怀疑是这个电源线的问题。绿联重新买了几根线,等到了再试试。
参考文章:
- https://answers.microsoft.com/zh-hans/windows/forum/windows8_1-hardware/%E4%BA%8B%E4%BB%B6id129%E5%92%8C153/3d4be0c1-d67a-4c81-8367-acea9873f46d
- http://www.pwrusr.com/system-administration/solved-warning-the-io-operation-at-logical-block-address-for-disk-was-retried
- https://blogs.msdn.microsoft.com/ntdebugging/2013/04/30/interpreting-event-153-errors/
- https://www.wintips.org/how-to-fix-disk-event-51-an-error-detected-on-device-during-paging-operation/
- https://support.microsoft.com/zh-cn/help/2806730/disk-event-id-154-the-io-operation-failed-due-to-a-hardware-error